API Support
Just set thecache_control param in your respective message body:
Prompt Templates Support
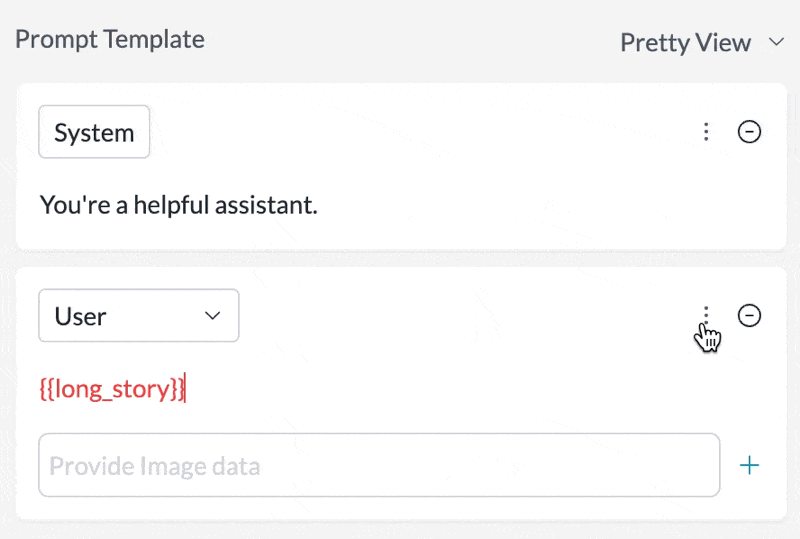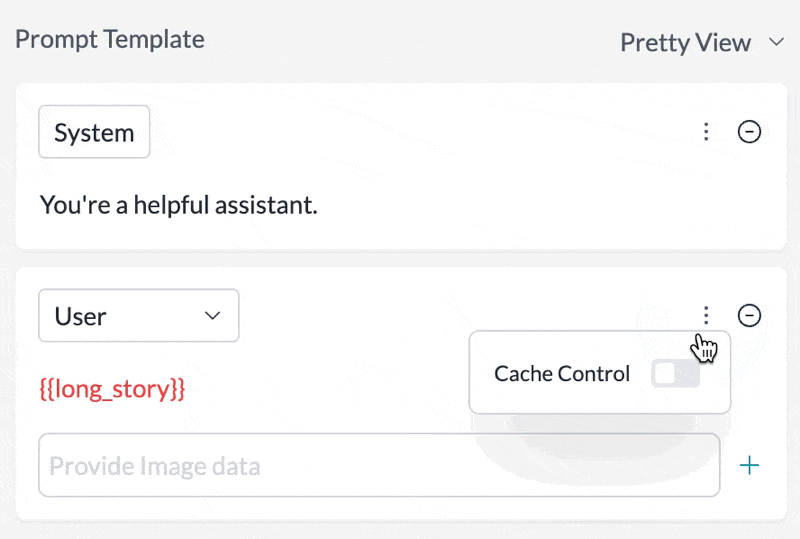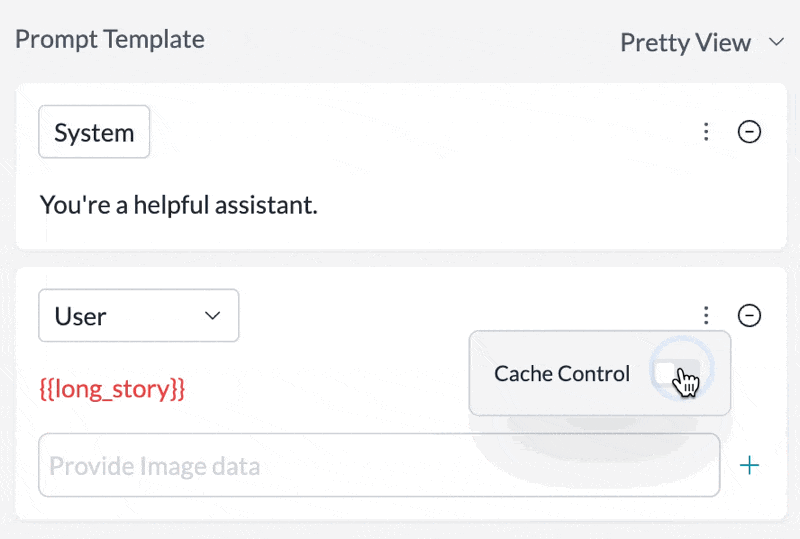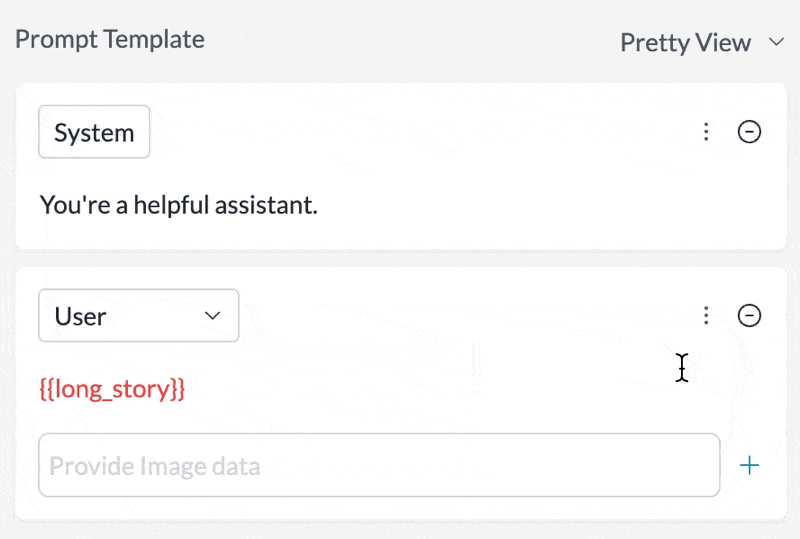
Set any message in your prompt template to be cached by just toggling theCache Control setting in the UI:
Anthropic currently has certain restrictions on prompt caching, like:
- Cache TTL is set at 5 minutes and can not be changed
- The message you are caching needs to cross minimum length to enable this feature
- 1024 tokens for Claude 3.5 Sonnet and Claude 3 Opus
- 2048 tokens for Claude 3 Haiku
Seeing Cache Results in Portkey
Portkey automatically calculate the correct pricing for your prompt caching requests & responses based on Anthropic’s calculations here: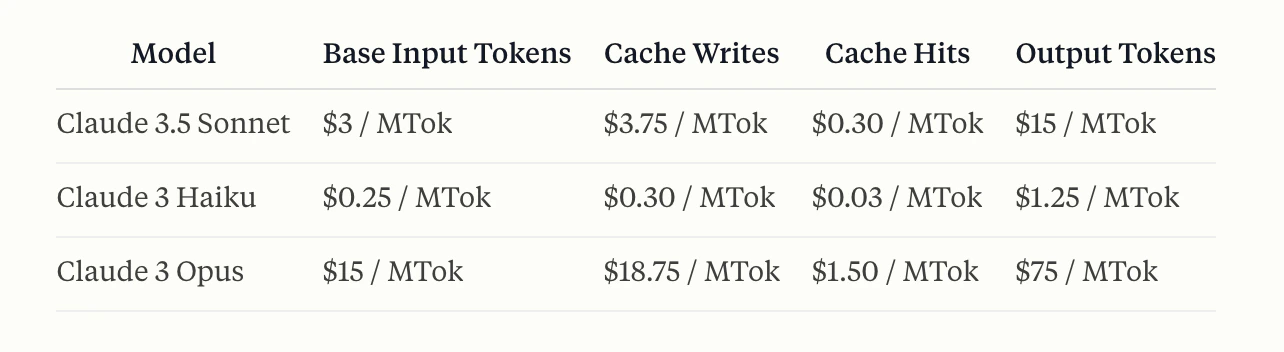
usage parameters:
cache_creation_input_tokens: Number of tokens written to the cache when creating a new entry.cache_read_input_tokens: Number of tokens retrieved from the cache for this request.
